introduction
This article refers to the address: http://
Content-based audio retrieval refers to the use of audio feature analysis to assign different semantics to different audio data, so that audio with the same semantics remains audibly similar. This technology has great application value in many fields. A common situation in retrieval systems is to apply a model trained in a quiet environment to an environment with actual background noise. Especially in the case of humming input, noise is unavoidable, so the audio recognition technology in the noise background environment has been receiving much attention. This paper presents an anti-noise audio retrieval system that connects audio enhancement and audio retrieval systems, focusing on the front-end anti-noise technology of content-based audio retrieval systems.
2 System platform establishment
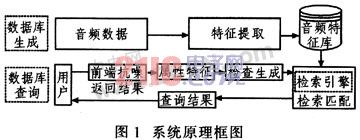
The content-based audio retrieval system uses multimedia information processing technology, combined with human perception psychology research and pattern recognition technology to achieve audio retrieval, including key steps such as audio segmentation, feature extraction and index retrieval. In the process of submitting the humming audio, it is inevitably disturbed by the noise introduced from the surrounding environment and the transmission medium, and the internal electrical noise of the device. These disturbances will degrade the performance of the retrieval system. Therefore, noise immunity must be applied to the noise band. The audio retrieval system first establishes a database for feature extraction of audio data. The audio search mainly adopts the singer query mode, and the user inputs the query information through the query interface, and then submits the query. Enhance the humming voice through the front-end anti-noise module before performing attribute feature extraction. Then the system extracts the features of the humming audio, and then the search engine matches the feature vectors, sorts them by relevance, and returns them to the user through the query interface. Figure 1 is a block diagram of the anti-noise retrieval system.
3 audio anti-noise technology analysis
3.1 Classification of speech enhancement algorithms
The input signal at the front end of the system is usually a humming input, and the voice band can be voice enhanced. Speech enhancement refers to the processing of noisy speech in order to improve the quality of noise-contaminated speech signals, and is mainly used to extract pure original audio or original speech parameters from noisy speech signals. According to different standards, speech enhancement algorithms have multiple classification methods.
The number of channels input from the signal is divided into a single channel speech enhancement algorithm and a multi-channel speech enhancement algorithm. In a single-channel speech system, both speech and noise exist in one channel, and speech information and noise information must be derived from the same signal. Common methods include spectral subtraction, signal statistical model method, auditory masking algorithm, Wiener filtering method, signal subspace algorithm and so on. The multi-channel speech enhancement algorithm uses the microphone array to acquire the signal data, which can make full use of the spatial characteristics of the array signal, the speaker position and the like, and combine the characteristics of the speech signal and the noise to realize the speech enhancement. Representative algorithms include adaptive beamforming algorithms, combined beamforming and post-filtering algorithms, and various signal-based subspaces, statistical model algorithms, and the like.
Another classification method is based on the different processing methods of speech signals, and the speech enhancement algorithms are divided into two categories: time domain speech enhancement algorithm and transform domain speech enhancement algorithm. Time domain speech enhancement is to directly process noisy speech in the time domain to recover pure speech, and use the short-term stationary characteristics and correlation characteristics of speech signals in the time domain to study targeted noise cancellation techniques. The representative algorithm has the largest algorithm. A posteriori probability estimation method, Kalman filtering method, comb filter method, subspace method, adaptive noise cancellation algorithm, speech generation model, and the like. Transform domain speech enhancement requires an appropriate transform to convert the speech signal into the transform domain, then recovers the pure speech component for the characteristic design of the noisy speech component in the transform domain, and finally obtains the pure speech signal in the time domain through the corresponding inverse transform. Estimated. The commonly used transforms include discrete Fourier transform, discrete cosine transform, KL transform and wavelet transform. Representative algorithms include spectral subtraction, Wiener filtering, MMSE estimation of short-term spectral amplitude, adaptive filtering, etc., and enhanced auditory masking effects. Algorithm, wavelet transform algorithm, speech enhancement technology based on frequency domain blind source separation. There are also new methods, such as neural networks, fractal theory, and so on.
3.2 Determination of system anti-noise algorithm
In the content-based audio retrieval system, the user inputs the retrieval information by means of humming, etc., and the single-channel speech enhancement algorithm based on single microphone input is a simple and practical form. The transform domain speech enhancement algorithm can make full use of the feature difference between the speech and background noise in the transform domain and its more significant in the time domain, and can effectively eliminate the correlation characteristics of the speech signal in the time domain, so it is effective for the noisy speech. The enhancement effect is better than the time domain speech enhancement algorithm. Therefore, the system is suitable for spectral subtraction, auditory masking, Wiener filtering, and signal subspace algorithms.
Wiener filtering can improve the spectral estimation of the stationary segment. The residual noise is similar to white noise and reduces the interference of music noise. However, the algorithm has a large complexity and is suitable for occasions where the real-time performance is not high. The auditory masking algorithm can reduce unnecessary speech distortion. In practical applications, the masked threshold can only be estimated by using noisy speech. The error of the estimation result is large, and the noise estimation is high. The signal subspace algorithm can effectively remove the background noise in the noisy speech, and the quality and intelligibility of the speech are greatly improved, but the calculation amount is large. The spectral subtraction algorithm is simple, the algorithm complexity is low, the implementation is relatively easy, and the real-time requirement can be satisfied to the greatest extent, but a large musical noise is introduced, which is suitable for use in a stationary noise environment and a situation requiring high real-time performance. Since the system is a real-time retrieval system, the requirements for real-time and rapidity are high, so spectral subtraction is used here.
4 Noise reduction based on spectral subtraction
4.1 Basic principles of spectral subtraction
Spectral subtraction subtracts the spectral components of the noise from the spectrum of the noisy speech signal in the frequency domain. The basic idea is to subtract the power spectrum of the noise from the power spectrum of the noisy speech signal under the condition that the additive Gaussian noise is independent of the short-time stationary speech signal, so as to obtain the enhanced pure speech spectrum. The basic principle block diagram is shown in Figure 2. In Figure 1, s(n) represents pure speech, d(n) represents additive noise, and r(n)=s(n)+d(n) represents noisy speech signal. Yk and Sk(k=0, 1, 2...) represent the spectral coefficients of the noisy speech signal and the pure speech, respectively, and λn(k) represents the power spectral coefficient of the noise.

Where α and β are parameters. When α=1, β=1, it is an amplitude spectrum subtraction form. When α = 2, β = 1, it is a power spectrum subtraction form.
This spectral subtraction is called traditional spectral subtraction. It is based on the insensitivity of the human ear to the sound phase. It subtracts the estimated noise from the noisy speech to achieve the purpose of speech enhancement. It is intuitive and simple, but it is easy to produce “music noiseâ€. Therefore, the improved algorithm of spectral subtraction is often used in practical applications.
4.2 Improved algorithm for spectral subtraction
After the speech signal is processed by power spectrum subtraction, noise remains in the frequency domain. To filter out or reduce these noises, the noise component can be appropriately subtracted, so that the residual noise is reduced in amplitude, thereby reducing the influence of noise. That is, the subtraction method. At this time, the formula (1) takes β>1, so that the speech distortion may increase. Therefore, the value of β is adjusted and determined by noise estimation. The principle of the value of β: For the noisy speech with low signal-to-noise ratio, the variance of the noise is large, β can be appropriately larger; for the noisy speech with high SNR, the value of β can be smaller. Since the estimation of the noise spectrum is an average value, the noise spectrum of the current frame is actually deviated from the estimated value. Therefore, the speech spectral value calculated by spectral subtraction may be a negative value. Generally, the result is set to zero, that is, a half wave is used. For the rectification method, the residual noise attenuation method can also be used. The amplitude of the noise residual is between zero and the maximum noise residual amplitude of the entire non-speech active period. Due to the randomness of the residual noise, the amplitude value of each frequency point is Different analysis frames randomly fluctuate, so the residual noise is compressed at a given frequency point by replacing the amplitude of the current frame with the minimum value of the frequency point amplitude of the adjacent frame. In this way, a system for improved spectral subtraction is formed, which can effectively achieve front-end noise reduction.
5 Conclusion
Content-based audio retrieval technology is more adaptable and has wide application value. The retrieval system with noise robustness is indispensable in practical applications. This paper presents an anti-noise audio retrieval system that cascades audio enhancement and audio retrieval systems, analyzes speech enhancement algorithms from different angles, and compares spectral subtraction as a front-end anti-noise technique for content-based audio retrieval systems. An improved algorithm for spectral subtraction.
Wind & Soalr Street light is a type of upgrade lighting, based on normal soalr street light, install a wind turbine inside, become wind and solar power support the whole hybrid lighting system. widely applied in lighting highway; roads; bridges; pedestrian streets and other occasions where good lighting effect is required.
Wind & Solar Street Light,Solar Lighting System,Hybrid Street Light,Wind Solar Hybrid Street Light
Yangzhou Urban New Energy Co.,Ltd , http://www.urban-solarenergy.com