Based on a scalable, task-independent system, OpenAI obtains optimal experimental results in a set of tasks that include different languages. The approach is a combination of two existing concepts: migration learning and unsupervised pre-training. These results demonstrate that supervised learning methods can be perfectly combined with unsupervised pre-training. This idea has been explored by many people in the past, and OpenAI hopes that the results will inspire more research and then apply this idea to larger, more diverse datasets.
Our system is divided into two phases: First, we train a migration learning model on large datasets in an unsupervised manner. During the training process, we use the language model's training results as signals, and then we have smaller, supervised datasets. Fine-tune this model to help it solve specific tasks. The development of this method was carried out after the work of our previous sentiment neuron. In the sentiment neuron task we noticed that unsupervised learning can be surprising by training the model with sufficient data. Distinguishing features. Here, we would like to further explore this idea: Can we develop a model that uses large amounts of data to train the model in an unsupervised manner, and then fine-tune the model to achieve good performance in different tasks? Our results show that the effect of this method is surprisingly good. The same core model can be fine-tuned for completely different tasks to suit the task.

This study is based on the method introduced in semi-supervised sequence learning. This method shows how to improve the ability of text categorization by unsupervised pre-training of LSTM and then supervised fine-tuning. It also extends ULMFiT's research, which shows how to fine-tune a single data-agnostic LSTM language model to achieve optimal performance on various text categorization data sets. Our work shows how to use the migration learning model in this approach to achieve success in a wider range of tasks beyond text classification, such as common sense reasoning, semantic similarity, and reading comprehension. It is similar to ELMo, but it is a task-independent problem. It contains pre-training and hopes to use a special model structure for the task to get the best results.
We achieve our goal by tuning a few parameters. All datasets use only one forward language model, without any combination, and most of the results use exactly the same hyperparameter settings.
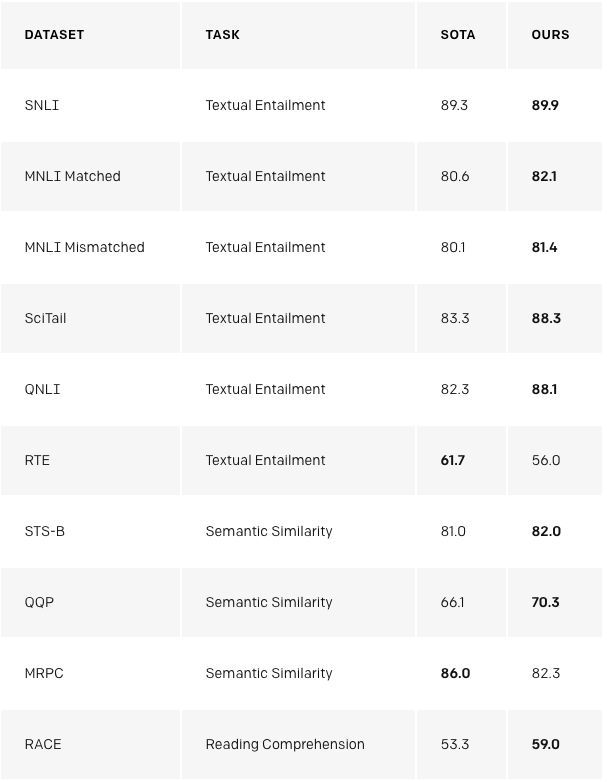
Our method performs particularly well on the three data sets of COPA, RACE, and ROCStories. These data sets are used to test common sense reasoning and reading comprehension. Our model obtains optimal results on these data sets. The identification of these data sets was considered to require multi-sequence reasoning and important world knowledge, which indicates that our model mainly enhances these capabilities through unsupervised learning. The above shows that unsupervised technology promises to develop complex language comprehension capabilities.
Why is unsupervised learning?
Supervised learning is at the core of the success of most machine learning algorithms. However, it requires careful clean-up of a large amount of data, and the cost of creating it is extremely expensive, so as to obtain good results. The attraction of unsupervised learning is that it has the potential to resolve these shortcomings. Since unsupervised learning eliminates the bottleneck of human explicit marking, it also expands the current trend well, which increases the computing power and usability of raw data. Unsupervised learning is a very active research field, but its practical application is often limited.
One of the most recent attempts was to attempt to further improve the language capabilities of the model by using unsupervised learning to enhance systems with large amounts of unlabeled data. The word representation through unsupervised training can use large data sets that contain terabytes of information, which, when combined with supervised learning, can improve the performance of various NLP tasks. Until recently, these unsupervised NLP techniques (eg, GLoVe and word2vec) used simple models (word vectors) and training signals (local occurrences of words). The skip-Thought vector is an early idea that is worth noting, showing the potential of how more sophisticated methods can be improved. And now using new technology will further improve experimental performance. The above techniques include the use of pre-trained sentences to represent models, contextual word vectors (especially ELMo and CoVE), and methods like ours: using a specific model architecture to unsupervised pre-training and supervised fine-tuning mix together.
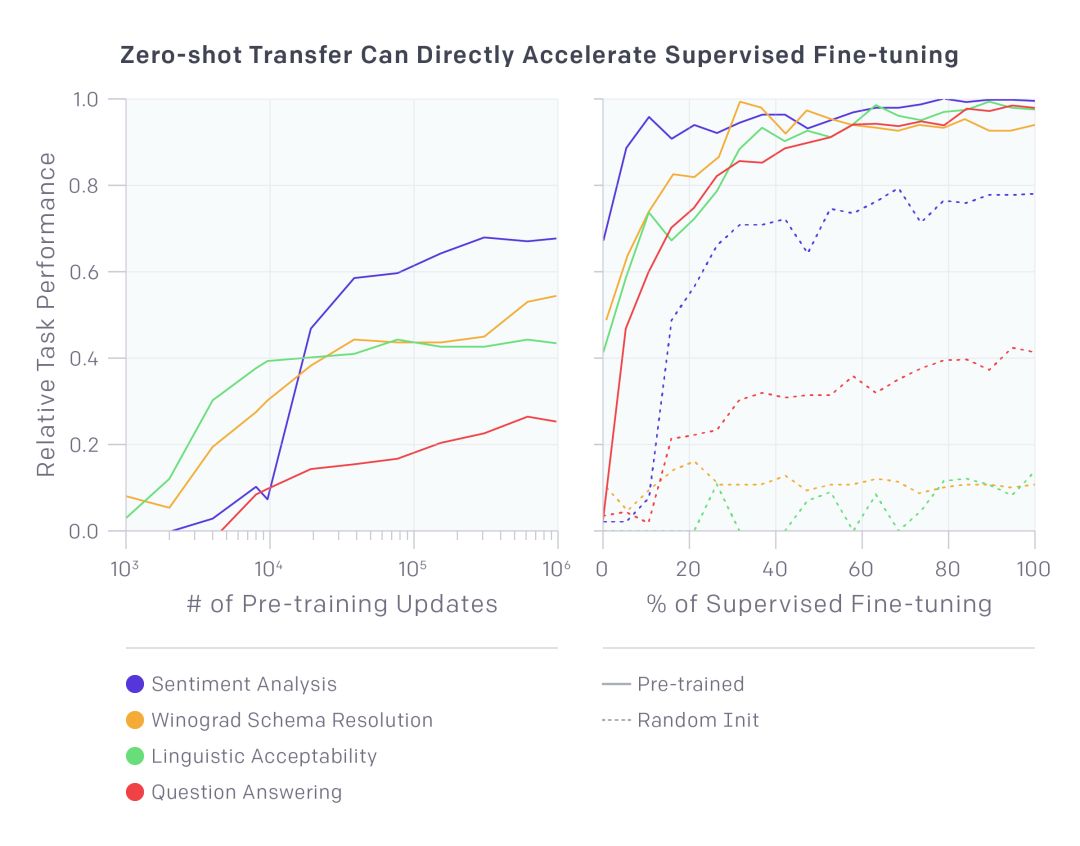
Pre-training our model on a large number of texts greatly improves its performance on challenging natural language processing tasks, such as Winograd pattern parsing.
We also noticed that we can use untrained basic language models to perform tasks. For example, as the basic language model improves, the performance of tasks such as selecting multiple correct answers will steadily increase. Although the absolute performance of these methods is still relatively low compared to the latest supervised technology (for Q & A systems, it performs better than a simple sliding window like the baseline system) but the encouraging point is that this behavior is extensive. The set of tasks is robust. Using these heuristics, random initialization networks that do not contain information about tasks and the world will not achieve better results than random initialization methods that include such information. This provides some insights and tells us why generating pre-training can improve the performance of downstream tasks.
We can also use the existing language features in the model to perform sentiment analysis. For the Stanford Emotion Treebank dataset consisting of positive and negative reviews, we can use the language model to enter the word "very" behind the sentence to guess whether the comment is positive or negative, and also see if the model has a predictive "positive" or The "negative" tendency. This method does not need to adjust the model according to the task at all. Its performance is comparable to the classic baseline, and the accuracy is about 80%.
Our work also validates the robustness and effectiveness of migration learning, which shows that it is flexible enough to be able to achieve a wide range of data tasks without the need to customize complex tasks or tune hyperparameters. The best result.
Shortcomings
There are some problems with this project that are worth noting:
Computing requirements: Many previous NLP task methods were started from scratch and relatively small models were trained on a single GPU. Our method requires expensive pre-training steps: 1 month of training on 8 GPUs. Fortunately, this training only needs to be performed once. We are releasing our model so that other people do not need to train such a model again. At the same time, compared to previous work, it is also a large model, so with more computation and memory, we used 37-tier (12) Transformer architectures, and we trained up to 512 tokens in sequence. Most experiments are conducted on 4/8 GPU systems. The model can quickly adjust new tasks, helping to reduce additional resource requirements.
Learn the world's limitations and data skewing in the text: Books and texts available on the Internet at any time do not contain complete or accurate information about the world. Recent work has shown that certain types of information are difficult to learn through text, while other work shows that models learn and use the skew contained in the data distribution.
Fragile generalization capabilities: Although our approach improves the performance of a wide range of tasks, the performance of current deep learning NLP models is sometimes counter-intuitive and shocking, especially when it comes to systematic, adversarial or distributed distribution. The way to conduct the assessment. Although we have observed some signs of progress, our methods are not immune to these problems. Compared to previous pure text neural networks, our method has superior lexical robustness. In the data set introduced by Glockner et al. in 2018, the accuracy rate of our model reached 83.75%, which is similar to the KIM method of integrating external knowledge through WordNet.
Looking to the future
Extension method: We have observed that the improvement of the performance of the language model is closely related to the improvement of downstream tasks. We are currently using a computer with 8 GPUs as hardware and only use thousands of books containing approximately 5 GB of text as training data sets. According to experience, using more computing performance and data can make the algorithm have much room for improvement.
Improved fine-tuning: Our approach is currently very simple. There may be substantial improvements if more sophisticated adaptation and migration techniques (such as those explored in ULMFiT) are used.
A better understanding of the principles of generative pretraining will benefit the model: Although we have discussed some of the ideas we have discussed here, more targeted experiments and research will help distinguish those different interpretations. For example, how much of the performance improvement we observed was due to improved ability to handle a broader context and improved world knowledge?
Ribbon Tweeter,Ribbon Tweeter Speaker,35W Sound Ribbon,Folded Ribbon Tweeter
Guangzhou BMY Electronic Limited company , https://www.bmy-speakers.com