
At the 2016 Computational Linguistics (ACL) Conference in Berlin, Germany, on August 7, scholars Thang Luong, Kyunghyun Cho, and Christopher D. Manning gave talks on Neural Machine Translation (NMT). Neural machine translation is a simple new architecture that allows machines to learn to translate. This method, although relatively new, has shown very good results and has achieved top performance in various language pairs. Neural networks have great application potential in natural language processing.
Kyunghyn Cho, one of the lecturers, and Yoshua Bengio, a deep learning student, and Junyoung Chung , a scholar from the University of Montreal , presented papers at the ACL conference to further demonstrate the findings of neural machine translation. Here, Lei Feng network (search "Lei Feng network" public number attention) for everyone to share the name "for neural machine translation, without explicit segmentation character level decoder" full paper.
Overview
Existing machine translation systems, both phrase-based and neural, rely almost exclusively on the use of explicit segmented, word-level modeling. In this paper, we present a basic question: Can neural machine translations not use any explicit segmentation when generating character sequences? To answer this question, we analyze a note-based encoder decoder in four language pairs - En-Cs, En-De, En-Ru, and En-Fi - with sub-level encoding And a character-level decoder using WMT's 15 parallel corpus. Our experiments show that models with character-level decoders outperform models with sub-word-level decoders on all four language pairs. Furthermore, the neural model with character-level decoders is superior to the most advanced non-neural machine translation systems on En-Cs, En-De, and En-Fi, and performs equivalently on En-Ru.
1 Introduction
Almost all existing machine translation systems rely on explicit segmented, word-level modeling. This is mainly due to the problem of data sparseness, which is more serious when the sentence is represented as a series of characters rather than words, especially for n-grams, since the length of the sequence is greatly increased. In addition to the sparseness of data, we often pretend that words, or their segmented lexemes, are the most basic units of semantics. It is natural for us to think that translation is the process of matching a series of source language words into a series of The target language words.
In the recently proposed paradigm of neural machine translation, this view has also continued, although neural networks are not dragged by character-level modeling, but they are affected by problems that are unique to the word-level modeling, such as the vocabulary of the target language. Very large, it will cause increased computational complexity. Therefore, in this paper, we investigate whether neural machine translation can be performed directly on a series of characters without explicit word segmentation.
To answer this question, we focus on characterizing the target as a sequence of characters. We evaluated the neural machine translation model on the four language pairs of WMT'15 using a character-level decoder, which made our assessment very compelling. We characterize the source language party as a sub-word sequence, extract it using the byte pair encoded from Sennrich et al. (2015), and change the target to a sub-word or character sequence. On the target side, we further designed a new recurrent neural network (RNN) called a dual-metric recurrent neural network that can better handle multiple time-scales in the sequence and additionally in a new, stacked recurrent neural network. Tested in the network.
In all four language pairs - En-Cs, En-De, En-Ru, and En-Fi - models with character-level decoders are better than models with sub-word-level decoders. We observed a similar trend in each of these configuration combinations, surpassing the best previous neurological and non-neural translation systems in En-Cs, En-De, and En-Fi, and implemented on En-Ru. The same result. We found that these results strongly demonstrate that neural machine translation can really learn to translate at the character level and can actually benefit from it.
2, neural machine translation
Neural machine translation refers to a recently proposed machine translation method (Forcada and Neco, 1997; Kalchbrenner and Blunsom, 2013; Cho et al., 2014; Sutskever et al., 2014). The goal of this method is to create an end-to-end neural network that takes the input as the source sentence X = (x1, ..., xTx) and outputs its translation Y = (y1, ..., yTy), where xt and yt' are Source and target flags. This neural network is built as a coding network and decoding network.
The coding network encodes the input sentence X as its continuous representation. In this paper, we closely follow the neural translation model proposed by Bahdanau et al. (2015), using a bidirectional recurrent neural network containing two recurrent neural networks. The feed forward network reads the input sentence in the feedforward direction as:
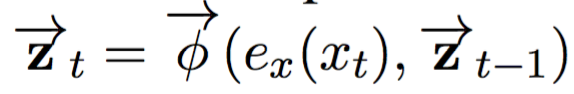
Where ex (xt) is a continuous embedding of the tth input symbol and is a cyclic activation function. Similarly, the reverse network reads sentences in opposite directions (right to left):
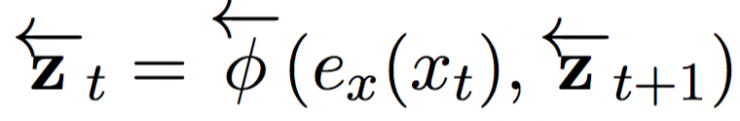
At each position of the input sentence, we connect the hidden states in the feed forward and reverse RNN to form a scenario group C = {z1, ..., zTx}, where
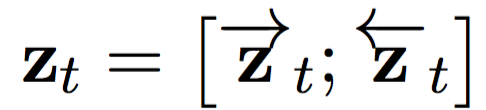
The decoder then calculates all possible translated conditional distributions based on this context group. First, rewrite the conditional distribution of a translation:
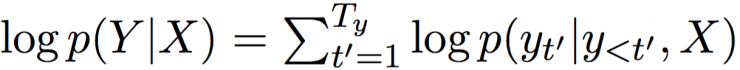
In each condition of the sum, the decoder RNN updates its hidden state by the following equation (1):
H't = φ (ey (yt' - 1), ht'-1, ct'), (1)
Where ey is a continuous embedding of a target symbol. Ct' is a scenario vector computed by the following soft stacking mechanism:
Ct' = falign ( ey (yt'-1), ht'-1, C) ). (2)
This soft alignment mechanism falign is based on what has been translated in Scenario C and weighs each vector according to relevance. The weight of each vector zt is calculated by the following equation (3):
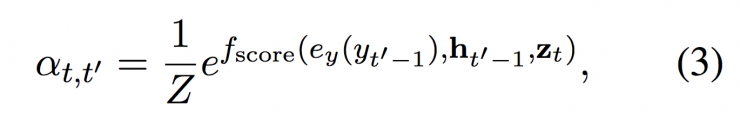
Where fscore is an argument function that returns a non-standardized score for ht'-1 and yt'-1.
In this paper, we use a feedforward network with a single hidden layer. Z is a standardized constant:
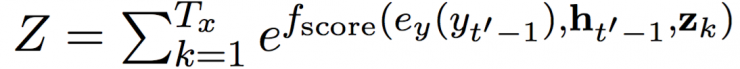
This process can be understood as calculating the alignment probability between the t'th target symbol and the tth source symbol.
In the hidden state ht' together with the previous target symbol yt'-1 and the scenario vector ct', a feed-forward neural network is entered, which brings the following conditional distribution:
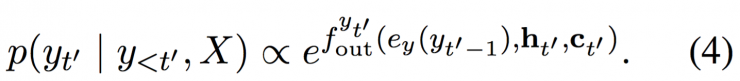
The entire model consists of encoders, code addition, and soft alignment mechanisms. After end-to-end debugging, the random logarithmic descent is used to minimize the negative log-likelihood function.
3, translate to character level
3.1 Motivation
Let us review how the source and target sentences (X and Y) are characterized in neural machine translation. For the source side of any training body, we can scan the whole to create a vocabulary Vx , which contains tokens assigned integer markers. The source sentence X then serves as a series of token-like tags belonging to the sentence, namely X = (x1, ..., xTx), where xt ∈ { 1, 2, ..., | Vx |}. Similarly, the target sentence is converted into an integer-labeled target sequence.
Each token or its index is then converted into a |Vx| so-called one-hot vector. With the exception of one, all elements in the vector are set to zero. The only index that corresponds to the token index is set to 1. This one-hot vector is what any neural machine translation model sees. The embedded function ex or ey is the result of applying a linear transformation (embedded matrix) on this one-hot vector.
An important feature of this one-hot vector-based approach is that neural networks ignore the underlying semantics of instructions. For a neural network, each instruction in a vocabulary is equivalent to the distance to each other instruction. The semantics of those instructions are learned (into embedding) to maximize the quality of the translation, or the log-likelihood function of the model.
This feature gives us a lot of freedom in choosing the unit of instructions. Neural networks have been proven to work well with word instructions (Bengio et al., 2001; Schwenk, 2007; Mikolov et al., 2010) and also work well with more subtle units such as subwords (Sennrich et al., 2015; Botha and Blunson, 2014; Luong et al., 2013) and symbols resulting from compression or coding (Chitnis and DeNero, 2015). Although a series of previous studies have reported the use of neural networks with characters (for example, studies by Mikolov et al. (2012) and Santos and Zadrozny (2014)), the mainstream method has always been to process text into a series of symbols. Each is associated with a series of characters, after which the neural network is characterized by those symbols, not characters.
Recently in neural machine translation, two groups of research teams have proposed using characters directly. Kim et al. (2015) proposed not to represent each word as a single integer instruction as before, but as a sequence of characters, using a convolutional network, followed by a high-speed neural network (Srivastava et al., 2015). Continuous representation of words. This method effectively replaces the embedding function ex, adopted by Costa-Jussa and Fonollosa (2016) in neural machine translation. Similarly, Ling et al. (2015b) used a bidirectional recurrent neural network instead of the embedding functions ex and ey to encode a sequence of characters from the corresponding continuous word representation and encode it into this continuous representation. Lee et al. (2015) proposed a similar, but slightly different method, in which each character is explicitly marked by the relative position of the character in the word, for example, "B" eginning and "I" in English words. Ntermediate.
Although these recent methods study the character level, they are still unsatisfactory because they all rely on understanding how to divide characters into words. Although this is generally relatively simple in English and other languages, this is not always feasible. This word segmentation process can be very simple, just like regularization with punctuation, but it can also be very complex, like morpheme segmentation, requiring a separate model to be pre-trained (Creutz and Lagus, 2005; Huang and Zhao , 2007;). Moreover, these segmentation steps are often fine-tuned or designed separately from the ultimate goal of translation quality, potentially creating sub-optimal quality.
Based on this observation and analysis, in this paper, we asked ourselves and readers an earlier question: Is it possible to perform character-level translation without using any explicit segmentation?
3.2 Why use word-level translation?
(1) Words as the basic unit of semantics
Words can be understood as two meanings. In an abstract sense, a word is a basic unit of semantics (a morpheme), and in another sense, it can be understood as a “specific word used in a sentence†(Booij, 2012). In the first sense, a word is transformed into a second meaning through the process of word morphology - including diacritical, combination and derivation. These three processes do change the meaning of morphemes, but they often remain similar to their original intentions. Because this view in linguistics holds that words are the basic units of semantics (as morphemes or derived forms), many previous studies in natural language processing have words as basic units and encode sentences as sequences of words. In addition, the potential difficulty in matching the character sequences and semantics of words may also drive the trend of such word-level modeling.
(2) Data sparsity
There is another technical reason that many of the previous studies on translation matching use words as the basic unit. This is mainly due to the fact that the major components of existing translation systems—such as language models and phrase lists—are based on probabilistic simulations of the number of words. In other words, the probability of the marker subsequence (or) a pair of markers is estimated by counting how many times it appears in the training volume. This method is seriously affected by the problem of data sparseness because of a large state space where subsequences grow exponentially and only grow linearly in training volume. This poses a great challenge for the modeling of character levels, since any subsequence will grow 4-5 times longer when characters (rather than words) are used. Indeed, the report of Vilar et al. (2007) suggests that expressions become worse when word-based machine translation systems use character sequences directly. More recently, Neubig et al. (2013) proposed a method to improve character-level translation using a phrase-based translation system, but with limited success.
(3) The disappearance of the gradient
Specifically for neural machine translation, the reason why word-level modeling is widely used is that one of the main reasons is the difficulty in modeling the long-term dependence of recurrent neural networks (Bengio et al., 1994; Hochreiter, 1998). When a sentence is used as a character representation, it is easy to believe that there will be more long-term dependencies in the future as the length of both sentences grows, and the recurrent neural network will be used in successful translation.
3.3 Why use character-level translation?
Why not use word-level translation?
The most pressing problem in the processing of word grades is that we do not have a perfect word segmentation algorithm for any language. A perfect word segmentation algorithm needs to be able to segment any known sentence into a series of morphemes and lexemes. However, this problem is a serious problem in itself and often requires decades of research (for Finnish and other morpheme-rich languages, see eg Creutz and Lagus (2005)), for Chinese, see Huang and Zhao (2007) Research). Therefore, many people choose to use a rule-based instruction method, or a non-optimal, but still feasible, learning-based segmentation algorithm.
The result of this non-optimal segmentation is that the vocabulary is often filled with words with similar meanings, sharing the same lexeme but different in form. For example, if we apply a simple command script to English, "run", "runs", "ran", and "running" (English running, normal, third-person singular, past tense, and present progress) ) are separate entries in the vocabulary, although they obviously share the same lexical "run". This makes it impossible for any machine translation, especially neural machine translation, to correctly and efficiently model these morphologically changing words.
In the specific case of neural machine translation, each word variant - "run", "runs", "ran", and "running" - will be assigned a d-dimensional word vector, producing four independent vectors, though If we can break those variants into one lexeme and other morphemes, obviously we can model it more efficiently. For example, we can have a d-dimensional vector for the lexical “run†and a smaller vector for “s†and “ingâ€. Each of these variants later becomes a loceme vector (shared by these variants) and a morpheme vector (shared by words with the same suffix or other structure) (Botha and Blunsom, 2014). This makes use of distribution characterization, which leads to better abstraction in general but seems to require an optimal segmentation, but unfortunately this is not always available.
In addition to the inefficiency in modeling, using (undivided) words has two additional negative consequences. First of all, the translation system does not abstract the neologism well and often matches an instruction reserved for unknown words. This actually ignores the semantics or structure of any word that needs to be integrated in the translation. Second, even if a lexical word is common, it is often observed in the training body that its morphological variant may not be necessarily. This means that the model will see less of this particular, rare word variant and will not be able to translate it well. However, if this rare variant shares a large part of the spelling with other more common words, we hope that the machine translation system can use those common words when translating rare variants.
Why use character-level translation
To some extent, all of these problems can be solved by directly modeling the characters. Although the problem of data sparsity arises in character-level translations, it can be elegantly solved by using a parametric approach based on a recurrent neural network rather than a word-based nonparametric approach. Moreover, in recent years, we have learned how to build and train a recurrent neural network through the use of more complex activation functions, such as the Long- and Short-Term Memory (LSTM) unit (Hochreiter and Schmidhuber, 1997) and the Threshold Cycle Unit (Cho et al. 2014) to capture long-term dependencies.
Kim et al. (2015) and Ling et al. (2015a) recently demonstrated that by using a neural network to convert character sequences into word vectors, we can avoid the emergence of many lexical variables as separate entities in the vocabulary. This is possible by sharing the "character to word" neural network among all unique instructions. A similar method was applied in machine translation by Ling et al. (2015b).
However, these recent methods still rely on obtaining a good (if not optimal) segmentation algorithm. Ling et al. (2015b) did say: "A lot of previous information about morphemes, cognates, rare word translations, etc. should be integrated."
However, if we use a neural network directly on undivided character sequences—whether it is circular, convolved, or a combination of them—there is no need to consider these previous information. The possibility of using unsegmented character sequences has been studied in the field of deep learning for many years. For example, Mikolov et al. (2012) and Sutskever et al. 2011) trained a recurrent neural network language model (RNN-LM) on character sequences. The latter proves that a reasonable text sequence can be generated only by sampling one character at a time from this model. Recently, Zhang et al. (2015) and Xiao and Cho (2016) successfully applied a convolutional network and a convolutional-cycle network to a character-level document, respectively, without any explicit segmentation. Gillick et al. (2015) further demonstrated that a recurrent neural network can be trained on unicode bytes (rather than on characters or words) for automatic partial annotation and named entity recognition.
These earlier studies allowed us to see the possibility of applying neural networks in machine translation tasks, which is often considered more difficult than document classification and language modeling.
3.4 Challenges and Problems
There are two overlapping sets of challenges for the source and target language parties. On the source language side, we still don't know how to create a neural network to learn highly nonlinear matches between spelling and sentence semantics.
There are two challenges in the target language. The first challenge is the same as the source language because the decoder neural network needs to summarize the translated content. In addition, character-level modeling of the target language side is more challenging because the decoder network must be able to generate long, coherent character sequences. This is a big challenge because the size of the state space increases exponentially with the number of symbols, and in the case of characters, there are often 300-1000 symbols.
All of these challenges should first be described as problems; the current recurrent neural network - which has been widely used in neural machine translation - can solve these problems. In this paper, our goal is to empirically answer these questions and focus on the challenges of the target (because both goals of the target will be shown).
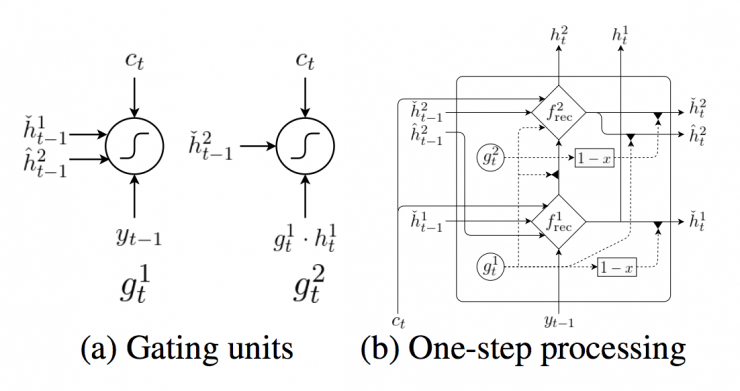
Figure 1: Two-metric circulatory neural network.
4, character level translation
In this paper, we try to answer the questions raised earlier by testing two different types of recurrent neural networks at the target (decoder).
First, we tested an existing recurrent neural network with a threshold cycle unit (GRU). We call this decoder a reference decoder.
In the second step, inspired by the threshold feedback network of Chung et al. (2015), we created a new two-layer recurrent neural network called the “double-metric†recurrent neural network. We designed this network to assist in the crawling of two timescales, the original intention being that the characters and words could be run on two separate timescales.
We chose to test these two options for the following two purposes. Experiments using a baseline decoder explicitly answer this question: whether existing neural networks can handle character-level decoding. This problem has not been well solved in the field of machine translation. Another option, the dual-metric decoder, has also been tested to understand if the answer to the first question is yes, then it is possible to design a better decoder.
4.1 Two-metric recurrent neural network
In this proposed two-metric recurrent neural network there are two sets of hidden units, h1 and h2. They contain the same number of units, namely: dim (h1) = dim (h2). The first group h1 uses a rapidly changing time metric (thus a faster tier), and h2 uses a slower time metric (thus a slower tier). For each hidden unit, there is an associated threshold unit, which we call g1 and g2, respectively. In the following description, we use yt'-1 and ct' for the previous target symbol and scenario vector respectively (see equation (2)).
Let's start with a faster layer. Faster Layer Outputs Two Activations, One Standard Output 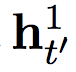 And its threshold version
And its threshold version 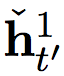 .
.
The activation of the fast layer is calculated from the following equation:
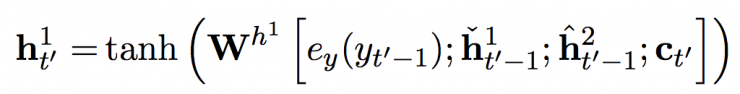
among them  with
with  Threshold activation for the fast and slow layers, respectively. These threshold activations are calculated from the following equations:
Threshold activation for the fast and slow layers, respectively. These threshold activations are calculated from the following equations: 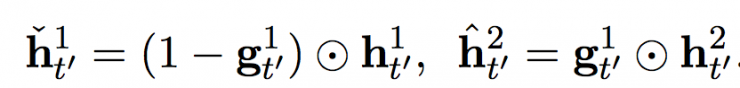
In other words, the activation of the fast layer is based on the adaptive combination of the fast layer and the slow layer in the previous time step. When the fast layer task needs to restart, ie
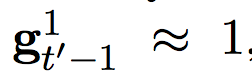
The next activation will be determined more by the activation of the slower layer.
The fast-level threshold unit is calculated from the following equation:

Where σ is a sigmoid function.
The slow layer also outputs two sets of activations, one regular output 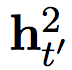 And its threshold version
And its threshold version  .
.
These activations are calculated from the following equations:

among them 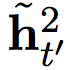 Is a candidate activation. The threshold element of the slow layer is calculated by the following equation:
Is a candidate activation. The threshold element of the slow layer is calculated by the following equation:
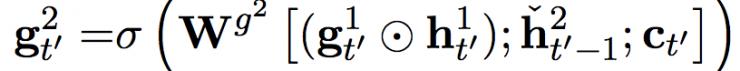
This adaptive fusion is based on a threshold unit from the fast layer, with the result that the slower layer updates its activation only when the fast layer restarts. This sets a soft limit that allows the fast layer to run faster by preventing the slow layer from updating while the fast layer is processing a current portion.
The candidate activation is then calculated from the following equation:
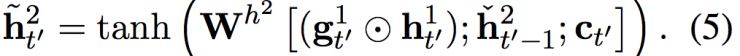

Figure 2: (left) BLEU scores on the length of the source sentence on En-Cs. (Right) Negative word log probability difference between sub-word level decoder and character level reference or dual-metric decoder.
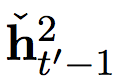 Means that the restart of the previous time step is similar to what happens in the fast layer.
Means that the restart of the previous time step is similar to what happens in the fast layer. 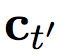 It is the input from the scenario.
It is the input from the scenario.
According to equation (5)  Only when the fast layer has finished processing the current part and is about to restart, will the fast layer affect the slow layer. In other words, the slow layer does not receive any input from the fast layer until the fast layer has finished processing the current part and is therefore slower than the fast layer.
Only when the fast layer has finished processing the current part and is about to restart, will the fast layer affect the slow layer. In other words, the slow layer does not receive any input from the fast layer until the fast layer has finished processing the current part and is therefore slower than the fast layer.
At each time step, the final output of the proposed two-metric circulant neural network is the combination of the fast and slow layer output vectors, ie: [h1; h2]. This combination vector is used to calculate the probability of distribution of all symbols in the vocabulary, as in equation (4). See Figure 1 for details.
5, experimental settings
To evaluate, we represent a source sentence as a sequence of sub-letter numbers, extracted using byte-pair encoding (BPE, Sennrich et al. (2015)), and encoding the target sentence as a series of BPE-based symbol sequences or a Character sequence.
Subject and pretreatment
We use all four parallel pairs of WMT'15 language pairs, En-Cs, En-De, En-Ru, and En-Fi. They consist of 12.1 M, 4.5 M, 2.3 M, and 2 M sentence pairs, respectively. Let's we instruct each subject to use a scripted script included in Moses. When the source language side is up to 50 subwords, and the target is up to 100 subword identifiers or 500 characters, we only use sentence pairs. We do not use any single language subject.
Table 1: BLEU scores for single model and combined sub-word levels, character-level techniques, and character-level dual-level decoders. The best score for a single model for each language pair is marked in bold and the best score in the combination is underlined. When available, we return the average, maximum, and minimum values ​​as subscript and superscript text.
For all pairs except En-Fi, we use newstest-2013 as a development test, and use newstests-2014 (Test 1) and newstests-2015 (Test 2) as test groups. For En-Fi, we use newsdev-2015 and newstest-2015 as development groups and test groups, respectively.
Models and Training
We tested three model settings: (1) BPE → BPE, (2) BPE → Char (benchmark), and (3) BPE → Char (double measure). The difference between the last two items is that we use different types of recurrent neural networks. We use GRU as an encoder in all settings. We used the GRU as a decoder in the first two settings (1) and (2), and the proposed two-metric cyclic network was used in the last setting (3). For each direction (feedforward and reverse), the encoder has 512 hidden units and the decoder has 1024 hidden units.
We used a random gradient descent with Adam to train each model (Kingma and Ba, 2014). Each update is calculated using a mini-batch consisting of 128 sentence pairs. The gradient is conventionally cut using a threshold of 1 (Pascanu et al., 2013).
Decoding and evaluation
We use bundle search to approximate the most likely translation of a particular source sentence. The bundle width is 5 and 15 for sub-word and character-level decoders, respectively. They are selected based on the development group's translation quality. Translations are evaluated using BLEU.
Multi-layer decoder and soft alignment mechanism
When the decoder is a multi-layer recurrent neural network (including a stacked network, and the proposed dual-metric network), the decoder outputs multiple hidden vectors {h1, ..., hL} at a time for the L layer. This allows an extra degree of freedom in the soft alignment mechanism (fscore in equation (3)). We use other options for evaluation, including (1) using only hL (slow layer) and (2) using all (bonded).
combination
We also evaluated the combination of neural machine translation models and compared it to the most advanced phrase-based translation systems in all four language pairs. We take a large average of the output probabilities for each step to decode from a certain combination.

Figure 3: The alignment matrix of the test case in En-De using the BPE → Char (double metric) model.
6, quantitative analysis
Slow layer for alignment
On En-De, we test which layer of decoder should be used to calculate the soft alignment. In the case of a sub-word level decoder, we did not observe any difference between the two layers of the selective decoder and the use of all layers (Table 1(ab)). On the other hand, with character-level decoders, we noticed that performance improved when only the slow layer (h2) was used for the soft alignment mechanism (Table 1(cg)). This means that aligning the larger part of the target with the source's subword unit will benefit the soft alignment mechanism. We use only the slow layer for all other language pairs.
Single model
In Table 1, we present a comprehensive report on the quality of translation for all language pairs, including (1) sub-word level decoders, (2) character-level reference decoders, and (3) character-level bimetric decoders. We can see that both character-level decoders are significantly better than sub-word-level decoders for En-Cs and En-Fi. On En-De, the character-level reference decoder is better than the sub-word-level decoder and the character-level dual-metric decoder, confirming the effectiveness of character-level modeling. On En-Ru, character-level decoders outperform sub-word-level decoders in a single model, but we observe that all three options are generally equal between them.
These results clearly demonstrate this: It is indeed possible to perform character-level translation without explicit segmentation. In fact, we observe that the translation quality at the character level often exceeds the translation at the word level. Of course, we once again mentioned that our experiments have limitations. The decoder only uses unsegmented character sequences. In the future, we need to study using an unsegmented character sequence instead of the source sentence.
combination
Each combination is built using 8 independent models. Our first observation is that in all language pairs, neural machine translation is equivalent to, or often better than, the most advanced non-neural translation systems. Moreover, character-level decoders outperform sub-word level decoders in all cases.
7 Qualitative analysis
(1) Can a character-level decoder generate long, coherent sentences?
Character translation is much longer than word translation and may make it more difficult for a recurrent neural network to generate coherent sentences as characters. This idea proved to be wrong. As in Figure 2 (left), there is no significant difference between the sub-word level and the character level decoder, although the length of the generated translation is generally 5-10 times longer in the character.
(2) Is a character-level decoder helpful for rare words?
One of the benefits of character-based modeling is that any sequence of characters can be modeled, thus allowing better modeling of rare word variants. We empirically confirmed this by observing the average negative logarithm probability of the sub-word level and the character-level decoder. As the frequency of words declines, the gap between the two increases. This is shown in Figure 2 (right) and explains one of the reasons behind the success of character level decoding in our experiments (we defined diff (x, y) = x - y).
(3) Can the character-level decoder soft-align between the original word and the target character?
In Figure 3 (left), we show an example of soft alignment of source sentences, "Two sets of light so close to one another". Clearly, the character-level translation model well captures the alignment between the source and target characters. We observe that the character-level decoder correctly aligns the "lights" and "sets of" when generating a German compound word "Lichtersets" (a combination of the lights) (see enlarged version in Figure 3 (right) ). This behavior also appears similarly in the English word "one another" and the German word "einaner" (editor's note: both meaning "mutually"), which does not mean that there is an alignment between the original word and the target character. Instead, this means that the intrinsic state of the character-level decoder—benchmarks or double metrics—perfectly captures the meaningful part of the character so that the model can match it to the larger part (sub-word) of the source sentence. .
(4) How fast does the character-level decoder decode?
We used the single Titan X GPU on the newstest - 2013 body (En-De) to evaluate the sub-word level reference decoding speed, character level reference, and character level dual-metric decoder. The sub-word level reference decoder produces 31.9 words per second, and the character-level reference decoder and the character-level dual-metric decoder generate 27.5 words and 25.6 words per second, respectively. Note that this is evaluated in an online setting, where we perform continuous translations and translate only one sentence at a time. Translating in batch settings may differ from these results.
8. Conclusion
In this paper, we study a basic problem, that is, whether a recently proposed neural machine translation system can directly handle translation at the character level without any word segmentation. We focus on the target, where one decoder needs to generate one character at a time while soft-aligning between the target character and the source subword. Our extensive experimentation utilizes four language pairs—En-Cs, En-De, En-Ru, and En-Fi—which are powerful proofs of character-level neural machine translation that are possible and actually benefit from it. .
Our results have a limitation: we use subcharacters on the source side. However, this allows us to obtain more detailed analysis, but in the future we must investigate another setting where the source party is also characterized as a character sequence.
Via ACL
Industrial Diesel Generator,Industrial Generators,Commercial Diesel Generators,Industrial Type Diesel Generator
Jiangsu Vantek Power Machinery Co., Ltd , https://www.vantekpower.com