The need for cellular network service providers to reduce operating costs is becoming more and more urgent, so field-programmable gate array (FPGA) operators are introducing SoC FPGA solutions that integrate embedded processors and importing more powerful digital pre-distortion (DPD) Algorithms help network equipment manufacturers build higher productivity products at lower power and cost.
Hive network operators are trying to increase network density through new transmission interfaces, transmission frequencies, higher bandwidths, and increasing the number of antennas and more wireless base stations, thus requiring a significant reduction in equipment costs. In addition, these operators need equipment with higher operational efficiency and network integration to reduce operating costs. Wireless infrastructure manufacturers are looking for devices that meet different requirements, seeking higher levels of integration, better performance, and greater flexibility while reducing power and cost.
Integration is the key to reducing overall equipment costs, but this must rely on high-order digital algorithms that increase the efficiency of the power amplifier to reduce operating costs. One of the most common algorithms is digital pre-distortion (DPD). As the configuration of the device becomes more and more complex, improving the operational efficiency of the device is a big challenge. With the advanced long-range evolution (LTE-Advanced) transmission technology, the wireless transmission bandwidth can reach 100MHz. If the manufacturer tries to combine multiple transmission interfaces with continuous spectrum configuration, the bandwidth can be even higher. The algorithms required for Active Antenna Array (AAA) and Remote Radio Unit (RRU) supporting Multiple Input/Output (MIMO) technology are increasingly demanding bandwidth. This article will explore how the industry's fully programmable system All-in-One (SoC) SoC components can boost performance gains for current and future digital pre-distortion systems, while also providing device manufacturers with ample programmability, low cost and low power consumption. And speed up the time to market.
Building a cellular wireless network
The industry's fully programmable SoC components incorporate a high-performance programmable logic (PL) architecture that includes a serial transceiver (SERDES) and a digital signal processor (DSP) module that integrates a hardware processing subsystem (PS). The hardware processing subsystem includes a dual-core ARM international Cortex-A9 processor, floating-point arithmetic unit (FPU) and NEON multimedia accelerators and a rich set of peripheral functions, including Universal Asynchronous Receiver Transmitter (UART), strings Peripheral functions required for complete wireless transmission such as column peripheral interface (SPI), internal integrated circuit (I2C), Ethernet (Ethernet), and memory controller. Unlike external general-purpose processors or DSPs, the interface between programmable logic and hardware processing subsystems has a large number of links, so the bandwidth can be very high; however, it is not feasible to handle these links with a stand-alone solution. In addition, fully programmable SoC components include hardware and software arrays, so the functionality required for remote wireless units can be built into a single chip, as shown in Figure 1.
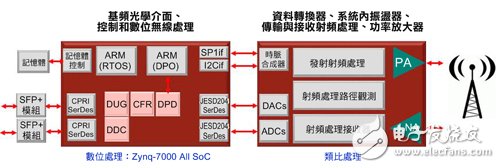
Figure 1 In this typical wireless architecture, all digital functions can be integrated into a single component.
The rich DSP resources in programmable logic can be used to implement digital signal processing functions such as digital up conversion (DDC), digital down conversion (DDC), crest factor suppression (CFR), and digital predistortion (DPD). In addition, the SERDES supports a 9.8-bit/s Universal Common Radio Interface (CPRI) and a 12.5-bit/s JESD204B for connecting the baseband and data converters.
The hardware processing subsystem supports both symmetric multiprocessing (SMP) and asymmetric multiprocessing (AMP). In this case, an asymmetric multiprocessing mode is scheduled, because one of the ARM Cortex-A9 processors is used to build substrate level control functions such as message termination, scheduling, set level, and alert execution (bare metal Or more likely an operating system such as Linux). Another ARM Cortex-A9 processor is used to build some digital pre-distortion algorithms because the digital pre-distortion algorithm does not guarantee a hardware solution as a whole.
Digital predistortion can increase the power amplifier efficiency by expanding its linear range; when the driver amplifier further increases the output power, the operating efficiency can be improved, and the static power consumption will remain relatively normal. Digital predistortion expands its linear range and uses the analog feedback path in the amplifier and a number of digital processing functions to calculate the inverse nonlinear coefficient of the amplifier. These coefficients are then used to pre-correct and drive the power amplifier's transmission signal, which ultimately increases the linear range of the amplifier.
Digital predistortion is a closed loop system that takes the previous transmission signal to determine the amplifier and the transmission method of these transmitted signals. The first task of digital predistortion is to have the amplifier agree with the previous transmission signal, which is done in a calibration module. Before performing any algorithm operation, the system will use the memory to calibrate the data; once the data is properly calibrated, the automatic correlation matrix operation (AMC) and coefficient calculation (CC) algorithm can be used to establish the inverse nonlinear coefficient of the power amplifier. Recent value. Once the coefficient is output, the data path predistorter uses the data pre-calibration to be transmitted to the power amplifier.
Accelerated estimation of digital predistortion coefficients
Of course, these features can be built in many different ways. Some are more suitable for software, while others are suitable for hardware, but also for both hardware and software; however, in the end, it is necessary to determine the method of implementation with the required performance. The use of fully programmable SoC components allows system designers to freely control the optimal use of hardware and software. In the case of digital predistortion, data path predistorters with high-speed filtering are typically built into programmable logic to generate a digital predistortion coefficient calibration and estimation engine due to the very high sampling rate required. It can then be executed in the ARM Cortex-A9 processor in the hardware processing subsystem.
In order to decide what hardware or software build method is required, you must first set which parts require software. Figure 3 shows the portion of the digital predistortion algorithm that requires the software to be set up in order to achieve the three functions shown in Figure 2. According to the setting in Figure 3, it is not difficult to understand that the digital predistortion algorithm has 97% of the time to perform the autocorrelation matrix operation, so it is natural to accelerate this process as a top priority.
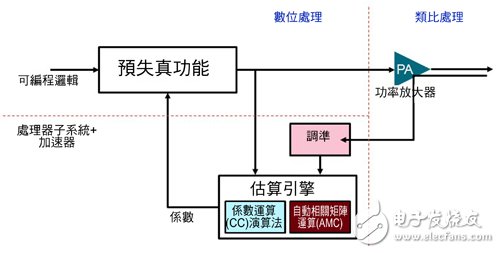
Figure 2 Digital predistortion system subdivided into different functional intervals
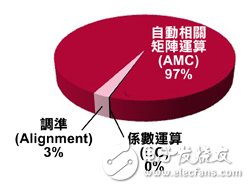
Figure 3 Software settings for the specified software operation in digital predistortion processing
The ARM Cortex-A9 processor performs more functions with rich computing resources that help improve performance. For example, in the hardware processing subsystem, each ARM Cortex-A9 processor contains a floating point unit and a NEON multimedia accelerator. The NEON unit is a 128-bit single instruction multiple data (SIMD) vector coprocessor that can execute two 32&TImes; 32b multiply instructions simultaneously; since the NEON unit is used for multiplication accumulation (MAC) operations, it is very consistent with the autocorrelation matrix. Required for computing functions. The software Intrinsics is available through the NEON module, which eliminates the need to write low-level programs when the system is assembled. Therefore, the use of more functions in the hardware processing subsystem can greatly improve the performance than software processors such as Microblaze or external DSP processors.
Uni Directional Mic,Uni Directional Microphone,Uni Directional Dynamic Microphone,Uni Directional Condenser Microphone
NINGBO SANCO ELECTRONICS CO., LTD. , https://www.sancobuzzer.com