MP3 is the abbreviation of audio compression layer 3 in MPEG-1 international standard. The mono bit rate is generally 64kbps. When the sampling rate is 44.1kHz, the compression ratio can be more than 12 times. It is widely used in many occasions such as the Internet. . Because decoding is much simpler than the encoding process, MP3 players or Walkmans can be seen everywhere, but MP3 encoding is implemented on the fixed-point DSP of the MCU, and the sound quality is rarely heard. Considering that the psychoacoustic model accounts for a large proportion of the entire MP3 audio coding algorithm, the author starts with simplifying the model, and uses a fast algorithm to reduce the amount of computation and data volume with coding, and to minimize the number of iteration cycles of coding. A real-time compression of MP3 is realized on a TMS320C549 chip of Texas Instruments, which is played back with standard decoding software. Subjective evaluation can achieve sound quality close to CD for normal audio.
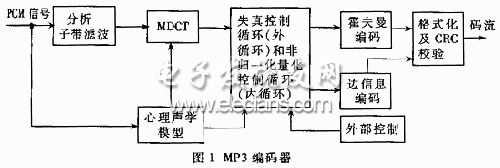
1 MP3 encoding algorithm and processing Figure 1 is a system block diagram of the MP3 encoder. Each channel is processed with 1152 samples for one frame. First, the analysis subband filter uses a quadrature mirror filter bank to divide the signal of the bandwidth of about 20 kHz into 32 subbands of equal bandwidth. Then the MDCT is applied to the sub-sample to compensate for the lack of sub-band filtering, mainly to improve the frequency resolution and eliminate the inter-band aliasing caused by sub-band filtering. At the same time, the sampled values ​​are calculated by the psychoacoustic model to determine the masking threshold of each frequency band.
The distortion control loop and the non-normalized quantization control loop are quantization quantization loop processes that reduce the precision of each MDCT coefficient by quantization, thereby reducing the number of coded bits. Different coefficients use different quantization steps, the frequency sensitivity from the ear sensitive frequency is high, the frequency sensitivity of the insensitive frequency is low, and the quantization error is not perceived by the human ear. The basis for selecting the quantization step is the masking threshold calculated by the psychoacoustic model.
Finally, the quantization order information and the Huffman code are packed into a bit stream for decoding.
So why does the masking threshold reflect the auditory characteristics of the human ear?
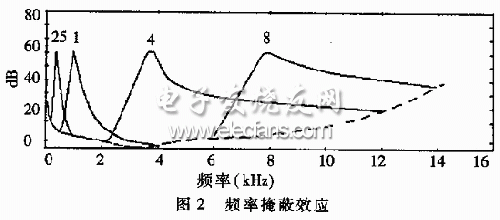
The auditory characteristics of the human ear involve problems in physiological acoustics and psychoacoustics. For example, the human ear feels different from the sound of different frequencies, which is a physiological problem, among which the sound of 2 kHz to 4 kHz is most sensitive, and the low frequency is more sensitive. The degree of sensitivity is embodied as a static masking threshold, as shown by the dashed line in Figure 2, which indicates the volume at which the sound of various frequencies is just heard in a quiet situation. There are masking effects related to human psychological perception. The masking effect refers to the phenomenon that the auditory feeling of one sound is affected by another sound, which is divided into temporal masking (forward and backward masking) and frequency masking (simultaneous masking). For example, when a strong sound stops, it takes a while to hear another strong sound. This is the time masking effect. Frequency masking refers to the effect of a sound on the sound of its adjacent frequency at the same time, as shown by the solid line in Figure 2. The solid line of the flag 1 indicates that when the masking sound of 1 kHz is 60 dB, the sound of different frequencies is just heard of the decibel value, and the closer the frequency is masked, the more the frequency is masked, and the low frequency is easier to mask the high frequency.
Therefore, the psychoacoustic model first uses FFT to analyze the frequency components contained in the signal, and adds the values ​​masked by all other frequency components at each frequency. The curve obtained by the connection is the masking threshold, which is a function of frequency. When the energy of a certain frequency component is below the curve, it cannot be felt by the human ear, then the frequency component can be encoded with zero bits; on the other hand, if the quantization step is selected, if the quantization noise is lower than the masking curve, it is not human ear. It is perceived that the larger the masking value, the larger the frequency component quantization step can be. Therefore, using the masked threshold as the basis for quantization coding, the quality of the compressed sound can be verified. Since the sound signal changes with time, the psychoacoustic model is calculated twice per frame signal, and a large amount of experimental test data is used, and the amount of calculation is conceivable.
2 Simplification and optimization of the algorithm 2.1 Fast algorithm for analyzing the subband filter The input of the subband filter is analyzed by 32 samples, and the output is an equally spaced subband sample of 32 frequencies. It first puts 32 sample values ​​into a first-in, first-out (FIFO) buffer of length 512; windowing the buffer; then accumulating every 8 values ​​in 512 caches, converting to 64 intermediate values; finally passing (1) Or convert 64 intermediate values ​​into 32 sample values:
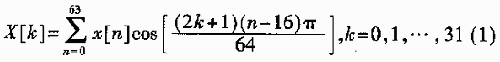
The key to finding a fast algorithm is this last step. Set the coefficients to an array:

It can be found that the array has the following symmetry: c[16+n]=c[16-n], n=0,1,...,16 (3) c[48+n]=-c[48-n] , n=0,1,...,15 (4) Therefore, if the combining coefficients are equal or opposite, the formula (1) becomes:

among them, 
It can be seen that the substitution of (5) instead of (1) can reduce the multiplication by half. It is also found that (5) is very similar to the standard IDCT, and the fast IDCT algorithm proposed by Lee can be slightly modified to derive the fast algorithm of (5). So the 32-point transform is broken down into the following two 16-point transforms: 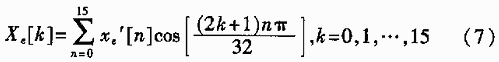
among them,

The final subband sample value is a butterfly combination as follows: X[K]=Xe[k]+(1/cos[(2k+1)Ï€/64]Xo[k],k=0,1,..., 15 (11) X[31-k]=Xe[k]-(1/cos[(2k+1)Ï€/64])Xo[k],k=0,1,...,15 (12) Direct calculation (1) requires 32 multiplications and 32 additions. The fast algorithm requires 2 multiplications and 15 additions. The calculation amount is 1/4 of the original amount, and the storage space occupied by the data table is reduced to about 1/8 of the original. .
Asic Miner Bitmain:Asic Miner Bitmain Ka3 166Th Kda Mining Machine
Bitmain is the world's leading digital currency mining machine manufacturer. Its brand ANTMINER has maintained a long-term technological and market dominance in the industry, with customers covering more than 100 countries and regions. The company has subsidiaries in China, the United States, Singapore, Malaysia, Kazakhstan and other places.
Bitmain has a unique computing power efficiency ratio technology to provide the global blockchain network with outstanding computing power infrastructure and solutions. Since its establishment in 2013, ANTMINER BTC mining machine single computing power has increased by three orders of magnitude, while computing power efficiency ratio has decreased by two orders of magnitude. Bitmain's vision is to make the digital world a better place for mankind.
Asic Miner Bitmain,Ka3 166Th Kda,Kda Miner Antminer Ka3,Asic Miner Ka3,ka3 miner
Shenzhen YLHM Technology Co., Ltd. , https://www.nbapgelectrical.com